Interpretation von Mittelwerten
Mittelwerte sind eine beliebte Darstellungsart bei Mitarbeiterbefragungen und Evaluationen. In einem fiktiven Beispiel möchte ich etwas näher drauf eingehen. Folgende Situation: In einem kleinem Betrieb, mit 16 Angestellten, der Medizinprodukte herstellt, wurde eine Mitarbeiterbefragung mittels Onlinfragebogen durchgeführt. Die Daten wurden statistisch ausgewertet. Im folgendem sind die Ergebnisse dargelegt.
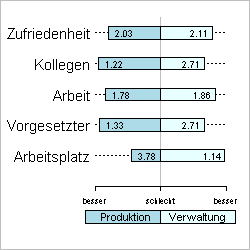
Im Diagramm sind die Mittelwerte der einzelnen Zufriedenheitsskalen im Vergleich der zwei Abteilungen Produktion und Verwaltung dargestellt. Die Werte sind so codiert, je höher der Skalenwert, desto größer die Zufriedenheit. Die Mittelwerte der Skalen Zufriedenheit setzt sich aus den “Bedingungen des Arbeitsplatzes“ , der Bewertung des “Vorgesetzter”, die Zufriedenheit mit der “Arbeit” und der Bewertung der zwischenmenschlichen Beziehung zu den Kollegen zusammen. Der Mittelwert der Skala Zufriedenheit mit der Arbeitssituation“ Zeigt bei den Mitarbeitern in der Verwaltung einen höherem Mittelwert m=2,11 als die Mitarbeiter aus der Produktion m=2,03. Aus dem vorliegenden Ergebnis kann geschlossen werden, dass in Beiden Abteilungen die Zufriedenheit mit der Arbeitssituation mit “gut” bewertet wird. (Ein Wert von 2 entspricht einer Bewertung mit gut.) In der Produktion werden aber die Bedingungen am Arbeitsplatzes sehr negativ bewertet m=3,78 was einer Bewertung mit “eher schlecht” entspricht. Fazit: Dem Betrieb geht es gut einzig in der Produktion sollte die Arbeitsplatzsizuation verbessert werden. Einen Schönheitsfehler hat die Interpretation das Ergebnis ist komplett falsch!!!
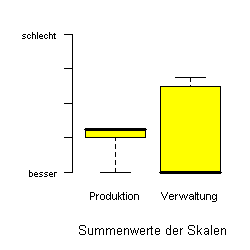
Wenn man schon Mittelwerte betrachten will, dann wenigstens einen Boxplot. Der ist zwar in dem Beispiel auch falsch aber im Plot ist wenigstens deutlich ersichtlich, dass die Werte bei den Mitarbeitern aus der Verwaltung stark streuen.
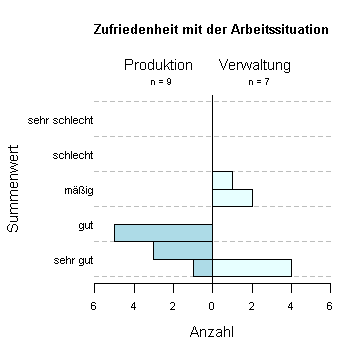
Eine andere genauere Möglichkeit der Darstellung, ist die Verteilung mittels Histogramm zu beschreiben. Durch eine geeignete Wahl der Klassengrenzen lassen sich gut die Unterschiede hervorheben. Die zwei Gruppen in meinem Beispiel sind gut zu vergleichen, man erkennt recht gut die “Lücke” bei den Mitarbeitern aus der Verwaltung.
Nachteil des Histogramms ist, dass bei Wahl der falschen Klassengrenzen die Interpretation erschwert wird und wenn man mehre Gruppen vergleichen will stößt man sehr schnell an die Grenzen des Histogramms. Eine Andere sehr gute Möglichkeit ist es die ECDF (Summenhäufigkeit) als Liniendiagramm darzustellen. (Oft wird auch der Begriff CDF (cumulative distribution function) oder kumulative Verteilungsfunktion verwendet). Im Prinzip ist die Summenhäufigkeit eine einfache Angelegenheit. Man summiert einfach alle Werte auf zeichnet sie in ein Diagramm und kann sofort alle Werte ablesen.
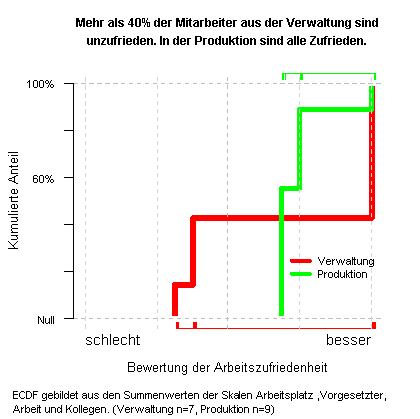
Das Diagramm ist von links nach rechts zu lesen alles was rechts liegt ist besser. Die Erste Linie startet bei den Mitarbeitern aus der Verwaltung uns steigt bis ca. 15% an. Das heißt 15% der Mitarbeiter aus der Verwaltung geben an sehr schlecht. Ein bisschen weiter rechte kommt der nächste Knick die Werte steigen bis 40%. Das heißt 40% geht es mindestens schlecht und so weiter. Die grüne Linie stellt sie Produktion dar, hier zeigt sich das es allen Mitarbeitern gut geht einigen sogar sehr gut. Interpretation: in der Verwaltung gibt es große Probleme 40% der Mitarbeiter sind unzufrieden. Der Produktion geht es trotz schlechterem Arbeitsplatz gut, die Mitarbeiter sind zufriedener. Ich will mit dem Beispiel nicht sagen, dass es prinzipiell falsch ist einen Mittelwert zu berechnen, ein Mittelwertdiagramm eignet sich hervorragend um einen schnellen Überblick zu gewinnen. Um Strukturen in einem Datensatz zu erkennen muss der Datensatz tiefer greifend analysiert werden und da reichen bunte Folien mit Balken nicht aus. (Die Daten zu dem Beispiel stammen aus einer realen Umfrage nur die Labels und Fragen habe ich geändert. Die Grafiken habe ich mit der freieren Statistik-Software R erstellt.)